如何统计一个网站的收录情况?
对于独立站,收录是排名的基础,所以,网站收录情况是大家第一个关心的事情。
我甚至有个很极端的观点:做网站就是做收录(请想象一下,如果你有N个网站,一共被收录了 千万个页面^_^)
有时候,出于数据分析和统计的需求,我们需要统计网站的收录情况(自己的或别人的)
那如何统计网站的收录情况呢?
方法1. 使用site指令
第一个想到的方法,当然是site命令了。
在Google搜索框中输入site:域名,例如site:ups.com。
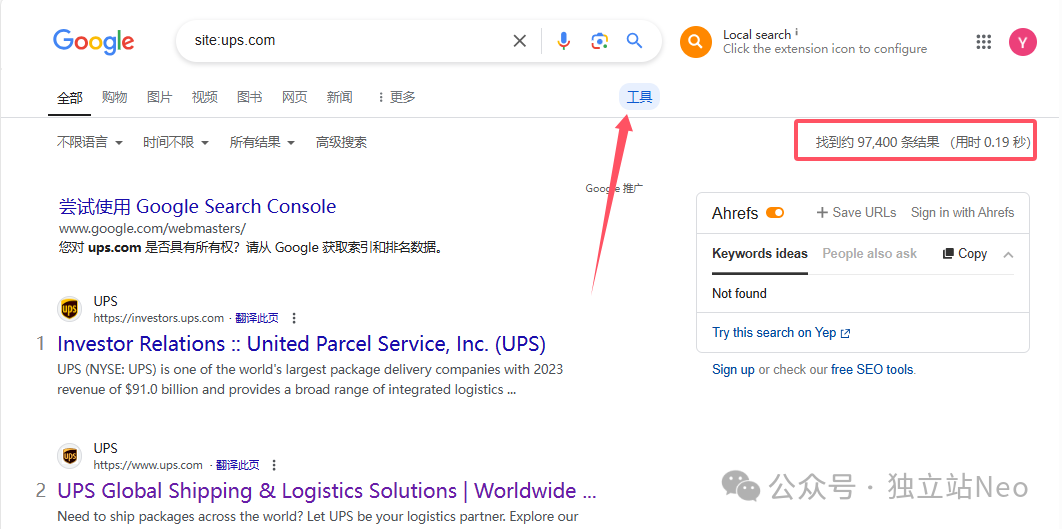
点击 “工具”按钮,会展示这个域名被收录的网页数量,但这个也不准确,有时候,误差会有几倍。
当然,你也可以直接site具体的url,比如:site:https://about.ups.com/us/en/our-company/our-history.html
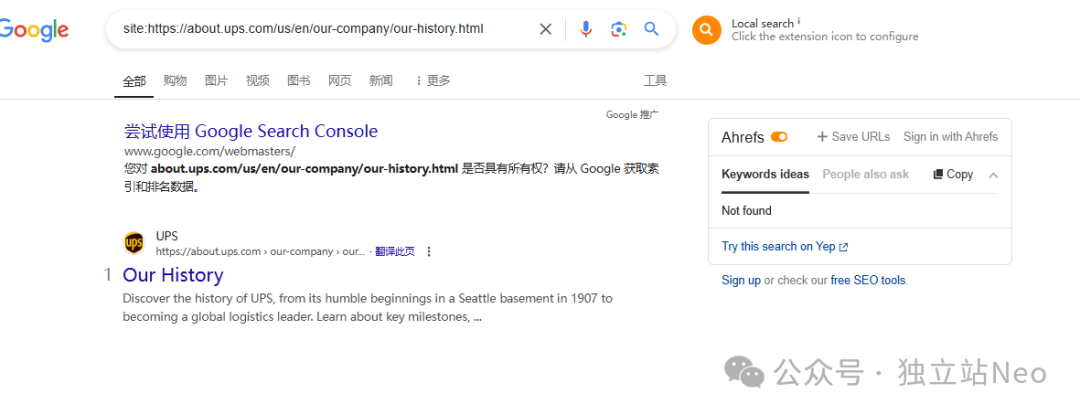
理论上 如果url被Google收录,结果中会显示该网站的结果。
但,请注意,这个的结果不一定准确,有时候你site的Url没有被收录,也会返回同一个网站的N个类似的Url结果。所以。。。。
因为这个原因,我之前特地写了个小工具,能精准检测site的结果页面(精确匹配url),可以提高准确性。
如果你想批量去检测url的收录情况,谷歌是有防爬机制的,一般检测50个url后,就要输入验证了,不适合大量检测统计。
方法2. 使用Google Search Console(谷歌站长工具)
-
如果是自己网站,更加准确的方法当然是 使用 Google Search Console 了。
-
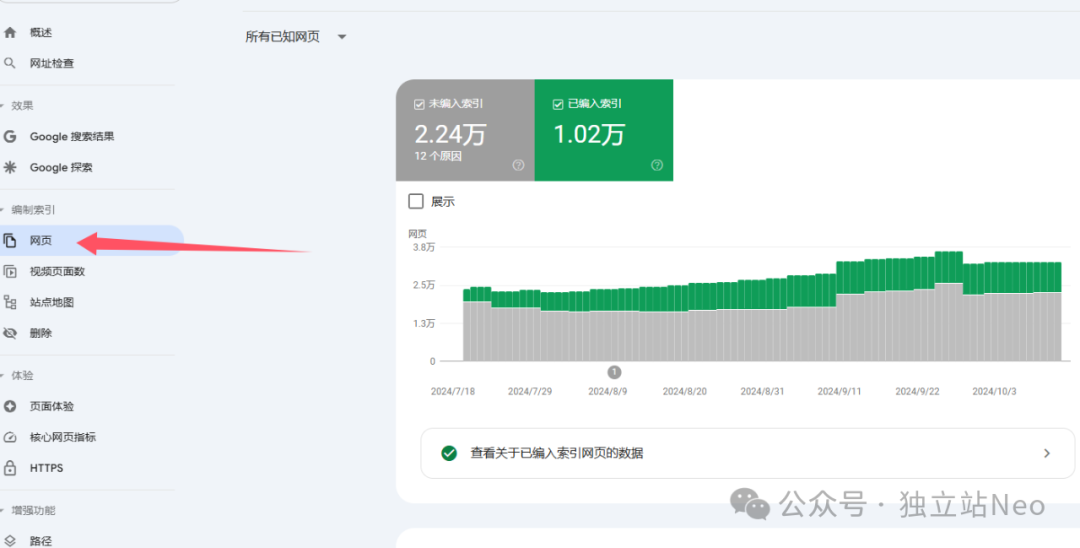
你可以在 “编制索引”--“网页”里,看到真实的整体收录情况
-
-
-
-
还可以查看具体的收录网页和未收录的原因
-
可惜,只能查看和下载1000条记录,很多时候,就不够用了。
另外,你还可以在顶部的查询框查询具体网页的收录情况。
方法3. Google 的 Search Console API
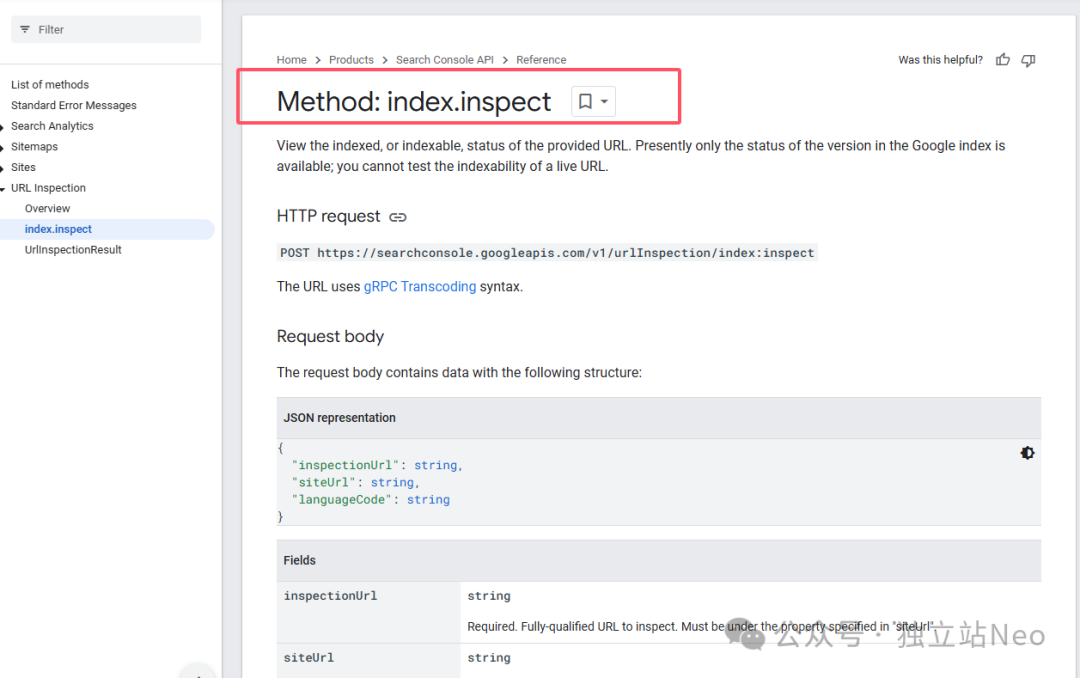
谷歌官方的Search Console API提供了接口,可以精确查询一个Url的收录情况,API返回的主要状态有:
-
Submitted and indexed(已收录)
-
URL is unknown to Google(谷歌没发现这个Url)
-
Crawled - currently not indexed(谷歌已经爬取了Url,但没索引,可能的原因:需要时间 or 网页质量差)
-
Discovered - currently not indexed(谷歌发现这个Url,但还没去采集)
-
Excluded by ‘noindex’ tag(谷歌没发现这个Url被noindex了)
-
Duplicate, Google chose different canonical than user
每天有2000次查询限额,对于一般的中小型网站,够用。
通过对接api,可以非常精确地分类统计网页的收录情况,了解网站整体情况。
方法4. 第三方工具
比如:Google Index Checker,SEO Site Checkup。。。。
-
并不准确,不适合用于数据分析,不推荐